Tensorflow How to Read Image to Text
Optical Grapheme Recognition Using TensorFlow

In this article nosotros'll be learning how to build OCR(Optical character recognition system using TensorFlow) and we'll also deploy the deep learning model onto flask framework.
Table of Content
- What is OCR?
- Data collection
- Building OCR Model
- Model Deployment
- Adding more data
- Limitation
- Future Extensions
Let's get started past introducing OCR.
i. What is OCR?
Standard definition of OCR from Wikipedia
Optical character recognition or optical character reader is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photograph of a certificate, a scene-photo or from subtitle text superimposed on an prototype.
Wait isn't it more than technical?
In simple terms OCR is the organisation that recognise text from images, scanned documents. It is unproblematic as that.
Nosotros'll know that data in everything in Deep Learning. And then, permit'southward observe some datasets for solving this problem.
ii. Data Drove
We're building a character based OCR model in this article. For that we'll exist using 2 datasets.
- The Standard MNIST 0–9 dataset past LECun et al.
- The Kaggle A-Z dataset by Sachin Patel.
The Standard MNIST dataset is already builtin in many deep learning frameworks like tensorflow, Pytorch, keras. MNIST dataset allow united states to recognize the digits 0–9. Each prototype containing single digits of 28 x 28 grayscale images.
MNIST doesn't include A-Z and then for that we're using dataset released by Sachin Patel on kaggle. This dataset takes the capital letters A-Z from NIST Special Database 19 and rescales them to be 28 x 28 grayscale pixels to exist in the same format equally our MNIST data.
Here is an image case of image present in this datasets.
Now let's directly jump into coding part.
3. Building OCR Model
- Loading Datasets
Let's build code for loading mnist dataset.
Each line of code in above code is cocky explanatory practise permit'south go farther.
Now we demand 1 more function to load A-Z dataset.
Once again this block of lawmaking is easy to understand with the assistance of comments.
let's phone call the function and our dataset is set.
2. Combining datasets and dataset preparation
Now we need to combine both the datasets for feeding into model. This can be done with few lines of code.
Here we're adding x to each label in a-z dataset because nosotros are going to stack them upwards with mnist dataset. Then we are stacking data and labels then our model compages needs images into 32 x 32 pixels so we've to resize information technology further we are calculation a channel dimension to every image and calibration the pixel intensities from [0–255] downwardly to [0–i]
Now we take to convert labels from integer to vector for ease in model fitting and see the count the weights of each character in the dataset and also count the classweights for each characterization.
iii. Performing Information Augmentation
We can improve the results of our ResNet classifier by augmenting the input data for training using ImageDataGenerator. We are using various scaling rotations, scaling the size, horizontal translations, vertical translations, and tilts in the images. Hither is a block of code through which we perform data augmentation.
Now our data is ready and so permit's build the heart of our Project i.e ResNet architecture.
4. Building ResNet Architecture
Hither is a custom implementation of resnet architecture.I'm not explaining entire architecture in this mail service.
five. Compiling model
let'southward initialise certain hyper-parameters for fitting our model.
EPOCHS = 50
INIT_LR = 1e-1
BS = 128 Then we'll fit the model with l epochs with initial learning rate of 1e-ane with batch size 128.
we are using stochastic slope descent optimiser for fitting our model with chiselled cross-entropy loss and we'll evaluate our model on the footing of accuracy. So, finally allow's fit the model.
Afterward about 3 hours of preparation on google colab with GPU I got 0.9679 accurateness at preparation gear up and 0.9573 accuracy at examination set up.
6. Model Evaluation
Training history
Above Graph looks pretty good which is the sign that our model is performing well on this task.
Permit's save this model so that we tin load it after.
model.salvage('OCR_Resnet.h5',save_format=".h5") Before jumping into model deployment let's check how our model is performing with actual images.
Here is a block of code that randomly get some images from the test set up and predict them with visualisation.
Have a look at output which I've obtained.

4. Model Deployment
At the end, we desire our model to be bachelor for the end-users so that they can make use of it. Model deployment is one of the terminal stages of our project. For that we used python spider web framework flask to deploy our model into web application.
Wait what is flask?
Flask is a spider web application framework written in Python. It has multiple modules that make it easier for a web developer to write applications without having to worry most the details like protocol management, thread management, etc.
Flask gives is a variety of choices for developing web applications and it gives us the necessary tools and libraries that allow usa to build a web application.
In order to build successful flask spider web-app first of all we take to create elementary website using HTML5, CSS3 and Javascript. We have converted the model which is in the course of a python object into a character stream using pickling. The idea is that this character stream contains all the information necessary to reconstruct the object in another python script.
Side by side office was to make an API which receives user's image though website and compute the predicted output based on our model.
Below is the flow diagram of entire awarding.

Let'southward now build the algorithm in guild to successfully deploy our model into spider web app.
How this thing tin be implemented
- Our model is trained in such a way that information technology recognize 1 grapheme at a time i.due east. It is a character based model. Only in real life user tin upload image containing entire words or even sentences. And so, in-order to perform precise predictions nosotros need to divide each and every grapheme from the image and feed it to the model to get predictions.
- Example

- From above prototype it is clear to exist clear that what exactly nosotros demand to do.
- Once we got a list of extracted characters we can and so resize each of them and feed information technology one by one onto the model and get predictions.
- Our web app will and so display the output.
Below is the unabridged lawmaking which perform this chore.
You can get entire source lawmaking for this project at my github repository .
Now let'south look at final web app.
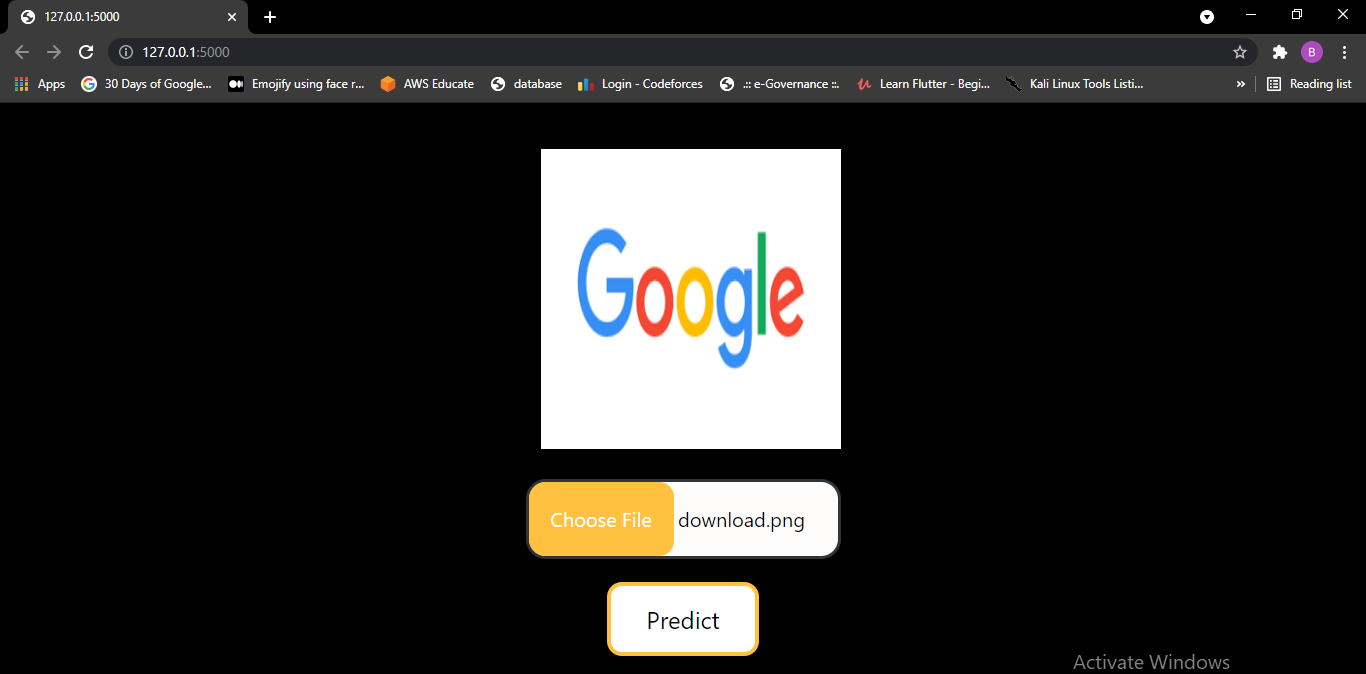
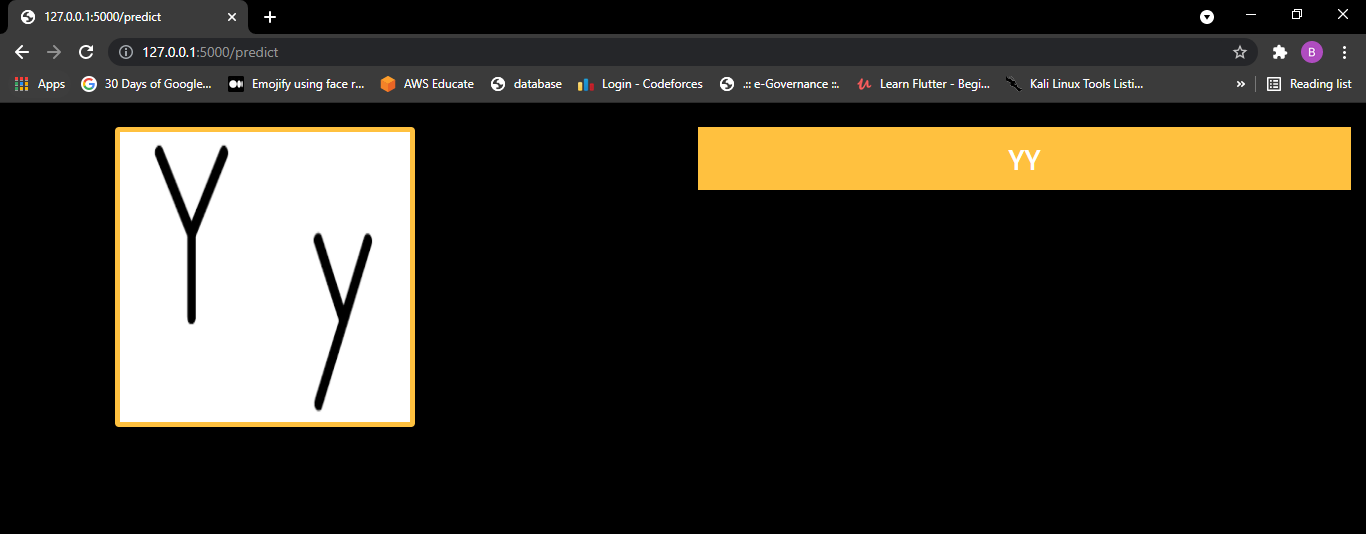
After clicking prediction button app.py file volition run and prediction will be shown in screen.
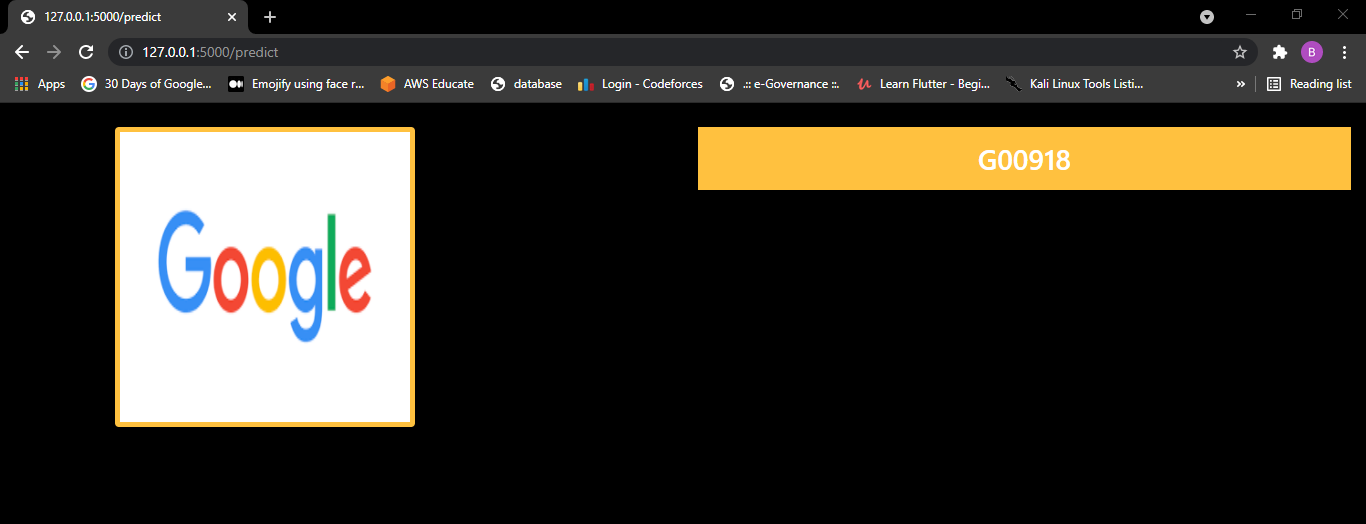
let's come across operation in one more than image.
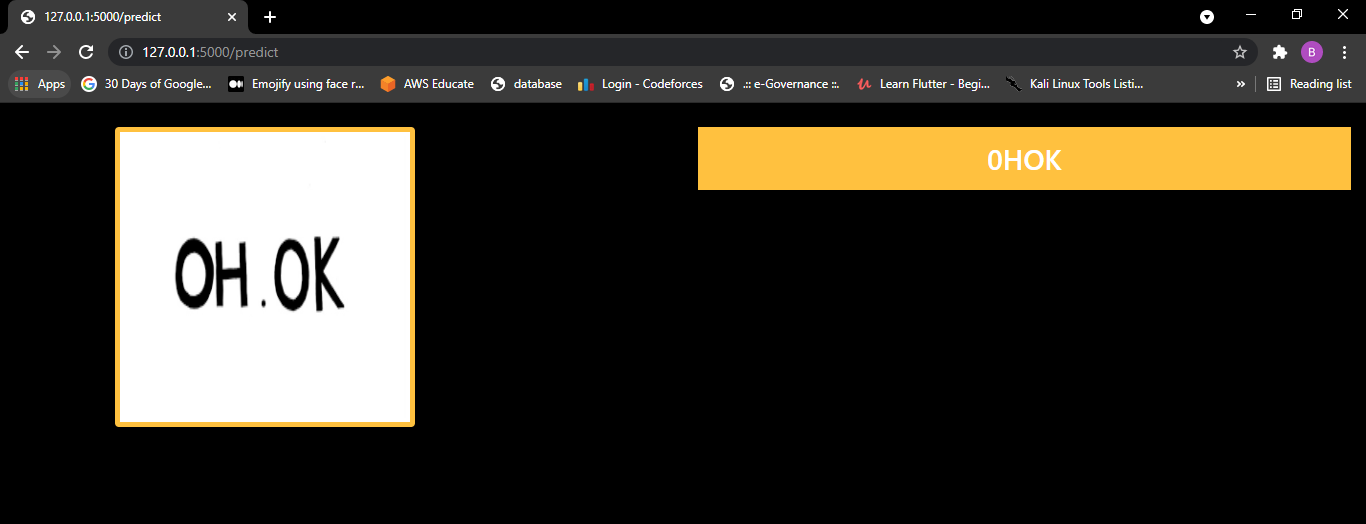
5. Adding more information
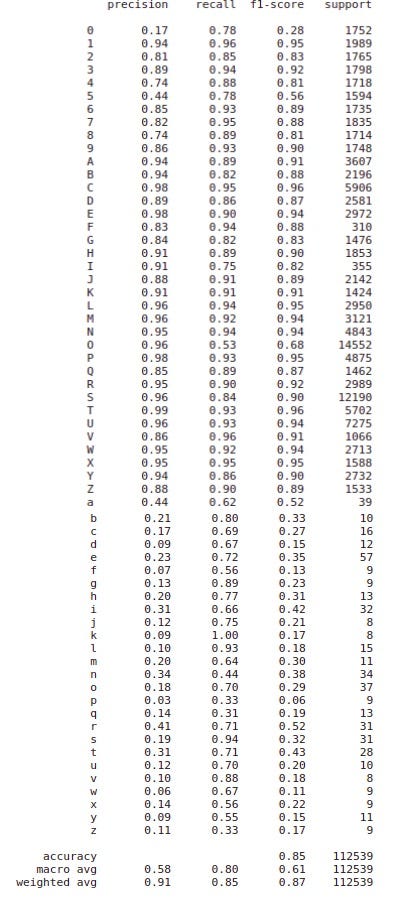
From prediction made by our model it is to exist seen that our model is notwithstanding very poor in recognising the characters. So, we need to practice something about information technology.
We've washed tone of experiments to better performance of this projection I've comprehend all of them.
Our model does not know that a-z pocket-sized alphabets are also exists then we need to add that data into our grooming dataset. Autonomously from this we can even add more than data of other characters likewise.
So in search of it we found a dataset containing all matter we needed over here. Then what we've done is we combine all the three datasets i.east
- Standard MNIST
- A-Z from kaggle
- English language char 74k dataset
By combining all of this datasets our dataset became vast and besides a-z characters were added. After that nosotros perform nevertheless stride as shown above and fit the model and got 85% accuracy on test set and models performance is also increased.
We can still increase the models functioning by plumbing equipment for more than epochs.
6. Limitations
- Our model tin fail if the image is very complex. Eastward.g. cursive writing images or images with continuous characters.
- Currently our model is trained on only english language and digits. So, if a user uploads an prototype of some other language and then it given wrong predictions.
We tin can solve this limitations by expanding this project.
7. Further Extension
- In guild to overcome the limitations nosotros can experiment with other neural network architectures and likewise combination of CNN and RNN i.east RCNN for prediction of continuous characters.
- Nosotros can also train on some larger dataset for increasing performance.
- For language other than english we can train our model with other linguistic communication dataset.
- We tin can also experiment with discussion based OCR technique which may exist more than effective than character based OCR.
This work is our internship work performed in at Bhaskaracharya Institute For Space Applications and Geo-Informatics in a team of myself, Prince Ajudiya and Yagnik Bhavishi.
I hope you lot got lot of useful information from this article.
Thank you for reading. 😃
Source: https://medium.com/analytics-vidhya/optical-character-recognition-using-tensorflow-533061285dd3
0 Response to "Tensorflow How to Read Image to Text"
Post a Comment